AI support for MtxVec
It is now possible to use AI LLM chats to convert existing code into MtxVec-accelerated form with very few errors and excellent performance. How does it work?
Getting started
ChatGPT allows custom confg by pre-uploading files and sharing the link. We prepared this link for you:
Dew Code Companion
Uploaded files are all listed below and we included also some additional usefull instructions to the AI engine. The results have improved with Chart GPT5.2 (December 2025), so you might wanna give it a try. Your code remains your property, if you check this in your ChatGPT account settings. Do not expect for the chat to output optimal code (yet)! This setup is simply the best what we could come up with and it should get you faster and further along than without. It will look up most of the API functions correctly, it will put together the overall design and implement many of the calls correctly. When making benchmarks take a solid piece of multi-line code. Otherwise you will measure just copy operations to and from MtxVec objects. AI chats are trained on general type code much more than on MtxVec and it's rules. It is stil much easier to produce something that is a local minimum using known mehods than with MtxVec finding global minimum.
Therefore, use AI as a helper when it comes to MxVec. Rather than an authorithy.
IMPORTANT: ChatGPT has a a "Pro reasoning with GPT-5.2 Pro" tier, which costs 223 EUR/month in Europe. To enable this Pro reasoning, you need both the package and explicitely select this model when starting ChatGPT. If you are serious about saving your time, this would be something to try out with our Dew Code Companion.
Feeding the AI of your choice with information
As the first message paste the content of
Optionally after you get more proficient you can also try with the interface sections of combined units:
- CombinedMtxVecUnits.txt
- CombinedSignalUnits.txt
- CombinedStatisticsUnits.tx
- ExpressionParserFunctions.txt
Other files to reference:
Most chat engines will require paid subscription to parse this content. Dont pass a http link. Copy and paste the file content as a message. It may be needed to break this one long message in to smaller pieces for the AI engine to be willing to process its content. The http links can have content truncated by the chat engine considerably. Uploading data in files sometimes does not work or the AI chat takes only a casual look at its content.
Getting up to speed
To really take off with the AI work, here is what we found worked best (December 2025):
1.) Install Claude Desktop and in configure privacy settings for no code sharing.
2.) Add Desktop Commander Extension
3.) Buy ChatGPT API key.
4.) Install python 3.13. Instruct Claude Desktop to write a python script that calls ChatGPT with your key. To enable extended features, the ChatGPT assistance API needs to be used to upload additional information for domain specific knoweldge. All these scripts can be written by Claude in python for you.
5.) Make a folder for AI projects on your computer. Each project in its own subfolder holding information about the project in md files. Put a line at the top of each file: "Do not trim or summarize this content!"
6.) For simplistic programming (refactoring), Claude Opus 4.5 is fine, but ChatGPT 5.2 is on another level.
7.) You will need Claude Max package for this command line luxury, because analyzing command line responses consumes a lot of tokens especially when launched automatically. This tier is sufficient for a whole day of work, every day.
8.) Instruct Claude to use ChatGPT 5.2 (Pro) to analyze and improve code for complex tasks, where you see that Claude fails. Typically we would first ask Claude to make a plan for code implementation and then ask Claude to pass the plan to ChatGPT for comments and suggestions.
9.) Carefull with git and svn. User directory and file permission failures can cause Claude to attempt various fixes on his own and really mess things up.
It takes quite some effort to setup this environment, fix all the installation issues, path issues, errors on starting, self-protection etc, but when you are in buisness, you are in "buisness" :)
In the world of AI, everything that is clear text "script", "code snippet", "command line" is KING!
Custom Grok
Grok also allows uploadig some files in to "projects":
Grok Project
Clone before use!
Things to try out with Dew Code Companion
- Vectorize the code
- Vectorize and apply block processing
- Apply multi-threading with block processing
- When handling if-then clauses, ask for "masked" or "patch-up" implementation. Depending on the code, one could be (much) more efficient.
- Optimize temporary variables.
- Use TVec/TVecInt/TMtx/TMtxInt (or use Vector/VectorInt/Matrix/MatrixInt depending on your preference.)
- Write benchmark and test comparing scalar and vectorized variant.
For your own protection
- Never assume, that AI knows something, that you won't need to know. It can make errors and write complete nonsense in a split second.
- Check if any of the calling objects are passed also as a parameter in the method. (This won't work.)
- The generated code may have very obvious additional optimization options. The more you know about which methods exist, the easier it is to spot them. Point out specific methods, if they could be used.
- Check for redundant Size calls. Most methods will also size the calling object internally.
- Before starting to vectorize and multi-thread the code, implement comprehensive tests of your own code and a benchmark. This will allow you to track progress.
- If you see some strange new function being called, ask to check for its existance.
We have prepared two examples. The first simpler example is on ChatGPT. The second example is running on Grok.
Example 1
Ask a question like this (using ChatGPT 5.2 or newer ideally from Dew Code Companion):
"Given:
procedure AddMy(const a,b,c: TDoubleArray);
var i: integer;
begin
for i := 0 to Length(a)-1 do
begin
c[i] := a[i] + 2*b[i]
end;
end;
Please write a variant of AddMy, that copies data from dynamic arrays and performs the operation using MtxVec vector type."
We get an answer, that looks like this:
This code actually compiles and works correctly. Now you can try this:
"Please vectorize:
xRMS := 0;
for i := 0 to Length(x)-1 do
begin
xRMS := xRMS + sqr(X[i]);
end;
xRms := sqrt(xRms/Length(x))
for i := 0 to Length(x)-1 do
begin
a[i] := X[i]*xScale + y[i]*yScale + z[i] + cos(X[i]);
end;
"
The answer we get:
// Compute RMS of x:
xRMS := Sqrt(x.SumOfSquares / x.Length);
// Compute a = X*xScale + Y*yScale + Z + cos(X)
a := AddScaled(x, xScale, y, yScale, z) + cos(x);
Note that the AI correctly found the AddScaled pattern, to reduce the number of temporary objects created during evaluation. Next command would be:
"Looks good, now also apply Block processing please"
Which will return this:
var sumSquares: double;
begin
// --- Compute RMS of x using block processing ---
sumSquares := 0;
x.BlockInit; // Initialize block processing on x
while not x.BlockEnd do
begin
// For the current block, add its sum of squares
sumSquares := sumSquares + x.SumOfSquares;
x.BlockNext; // Advance to the next block
end;
// After processing all blocks, compute the RMS:
xRMS := Sqrt(sumSquares / x.Length);
// --- Compute a = x*xScale + y*yScale + z + cos(x) using block processing ---
// Ensure 'a' is sized to match 'x'
a.Size(x);
// Initialize block processing on all vectors
x.BlockInit;
y.BlockInit;
z.BlockInit;
a.BlockInit;
while not x.BlockEnd do
begin
// For the current block, compute: a = x*xScale + y*yScale + z
a.AddScaled(x, xScale, y, yScale, z);
// Then add cos(x) element-wise to a
a.Add(cos(x));
// Advance all vectors to the next block
x.BlockNext;
y.BlockNext;
z.BlockNext;
a.BlockNext;
end;
end;
Next command would be:
Block processing only makes sense, when you can reuse a block multiple times in the same while loop. Try joining the two loops.
which, gives:
var
sumSquares: double;
begin
// Ensure 'a' is sized to match 'x'
a.Size(x);
sumSquares := 0;
// Initialize block processing on all vectors
x.BlockInit;
y.BlockInit;
z.BlockInit;
a.BlockInit;
while not x.BlockEnd do
begin
// Accumulate sum of squares for the current block
sumSquares := sumSquares + x.SumOfSquares;
// For the current block, compute:
// a = x * xScale + y * yScale + z + cos(x)
// Using compound operations for efficiency:
a.AddScaled(x, xScale, y, yScale, z);
a.Add(cos(x));
// Advance to the next block
x.BlockNext;
y.BlockNext;
z.BlockNext;
a.BlockNext;
end;
// Compute the overall RMS from the accumulated sum of squares
xRMS := Sqrt(sumSquares / x.Length);
end;
This is in fact correct and optimal answer. And the performance improvement:
- Original, not threaded time = 7.10ms
- Block vectorized and threaded = 1.27ms
- Block vectorized with methods and threaded = 1.13ms
Example 2
We start on grok.com by first pasting the prior knowledge text and then with:
After we ask for vectorization we finish with:
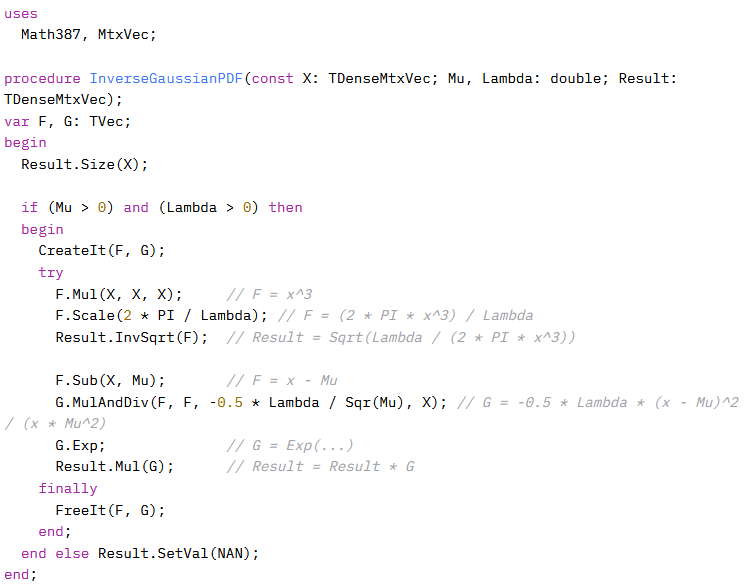
Here is what we had to do after the initial request for vectorization:
- Ask to use TVec/TMtx instead of Vector/Matrix for local vars. This allso allows for the posibility of multi-threading. The use of CreateIt/FreeIt uses separate memory pools per thread and allows linear scaling with thread count. CreateIt/FreeIt is also cca 10x faster than calling TVec.Create/TVec.Free.
- Request to remove the use of masks, because the result will be correct with NAN and INF, even without special handling.
- Multiple messages were needed to explore the joining of individual TVec methods in to more compound expressions. Many times the chat can report, that it overlooked an overload and appologize. We end up using InvSqrt, MulAndDiv and Mul with three params.
And here is how the initial response looked like:
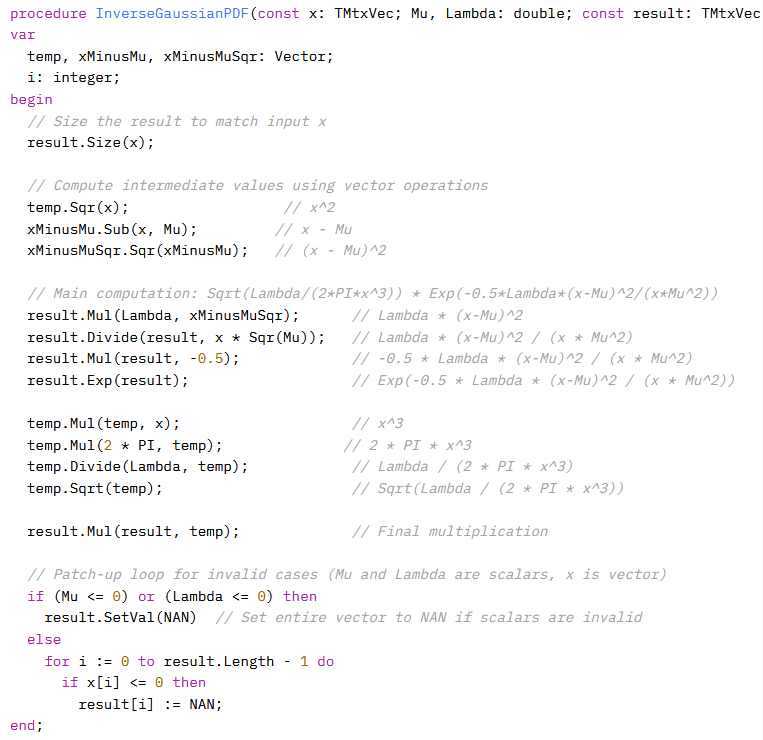
Note multiple cases of passing the calling object as a parameter instead of using an in-place variant of the method. (This will not run). The patch-up loop can be very performant and easy to use and understand, but sometimes the math will already produce the special numbers NAN and INF on its own. All other changes are related to the use of more compound vectorized expressions. And the benchmark?
- For 32bit we get a 16x improvement on one CPU core
- For 64bit we get 11x improvement on one CPU core
Plus retaining the possibility of linear scaling with CPU core count when multi-threading. Will this be faster than the output of the best C++ vectorizing compiler? Absolutely. It will be 2-3x faster than C++ unless some serious work with considerable experience would be done to optimize the vectorized function loop manually and it is not sure, that it will be possible to match the results.
Benchmarking considerations
- Be sure to include an error check, that the results between scalar and vectorized version are equal
- Compare performance on "valid function range", because typically you will not be computing on invalid data.
- Limit the length of vectors to 1000. This is to reflect the block length when using block processing. With block processing you can process vectors of any length at performance levels as if though their size was only 1000. Ask the chat to apply "block processing" to see what it does.
Comparison to vectorized Python
Basic guidelines when using one CPU core:
- When using Intel OneAPI IPP primitives line for line in both languages, MtxVec will be in worst case only 5x faster than Python.
- In a typical case MtxVec will be cca 300x faster than Python.
And considerations for multi-threading:
- MtxVec contains a number of mechanisms to achieve linear scaling with core count. 32 CPU cores, can give 32x faster code.
- Python will typically deliver an improvement of about 2x even when 32 CPU cores are available when multi-threading.
Although a comprehensive overview would be a big job, these are some numbers to start with.
(Last update, June 11th, 2025)